Data Mining
Data Mining refers to a process by which patterns are extracted from data. Such patterns often provide insights into relationships that can be used to improve business decision making. Data mining methods can be roughly grouped according to their use for clustering, classification, association, and prediction.
| Methodology |
| Association |
| Classification |
| Clustering |
| Prediction |
| Text Mining |
Clustering
Clustering refers to the process by which a set of cases are placed into natural groupings based upon their measured characteristics. Since the number of characteristics is often large, a multivariate measure of similarity between cases needs to be employed. Statgraphics provides a number of methods for deriving clusters, including nearest neighbor, furthest neighbor, centroid, median, group average, Ward's method, and the method of K-Means. The results may be displayed as a dendrogram, a membership table, or an icicle plot. Agglomeration plots are used to suggest the proper number of clusters.
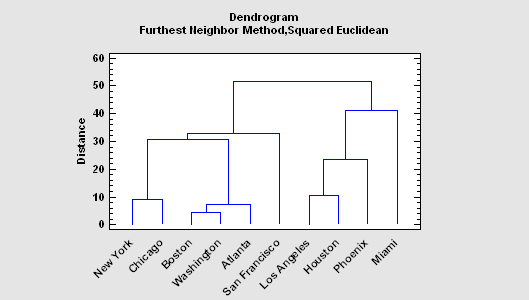
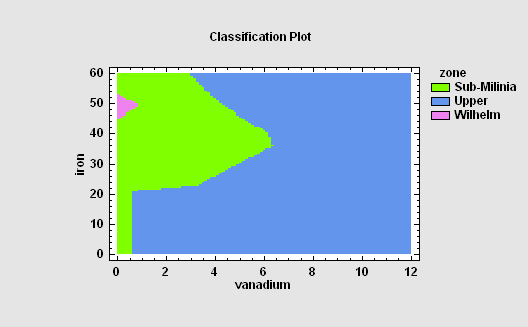
Classification
Classification is the process by which a set of cases are assigned to levels of a categorical factor based upon their characteristics. A training set of known cases is used to develop a classification algorithm which can then be used to predict which category unknown cases are most likely to belong to. For example, applicants for a loan might be placed into risk categories based upon their personal characteristics, given an algorithm developed from previous applicants. Popular methods include discriminant analysis and neural network classifiers.
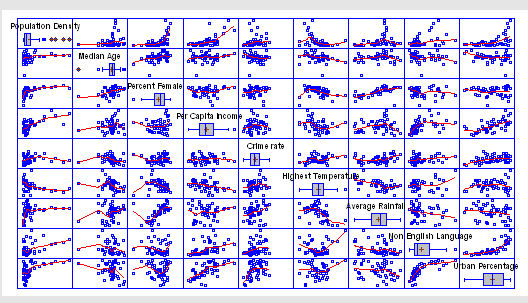
Association
Measures of Association are used to identify variables that are related to each other. If the factors are quantitative, correlation coefficients may be used. If the factors are non-quantitative, other measures of association are used. A matrix plot with nonlinear Lowess smoothers is shown at the right. Statgraphics includes statistics such as Pearson's product-moment correlation coefficient, Kendall and Spearman rank correlations, partial correlations, lambda, the uncertainty coefficient, Somer's D, the contingency coefficient, eta, Cramer's V, conditional gamma, Pearson's R, and Kendall's tau.
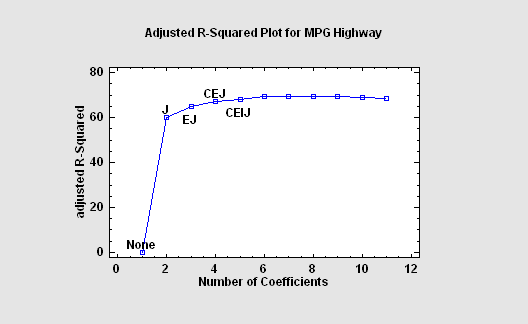
Prediction
Prediction refers to the development of statistical models that can predict the value of one variable given the values of other variables. Regression models of various sorts are often used. When the number of predictors is large, selection of a good model can be difficult. Statgraphics contains procedure that fit models involving all possible linear combinations of a set of predictors and select the best models using criteria such as Mallows' Cp and the adjusted R-squared statistic.
Text Mining
The Text Mining procedure analyzes one or more text columns or documents to determine how frequently various words are used. The main output of this procedure is an identification of those words that occur most frequently. Both tabular and graphical summaries are provided.
