Anomaly Detection (Outliers)
3 new machine learning procedures have been added to Version 20 to assist in detecting anomalies (outliers) in a data set. These procedures supplement the Outlier Identification procedure found in earlier versions.
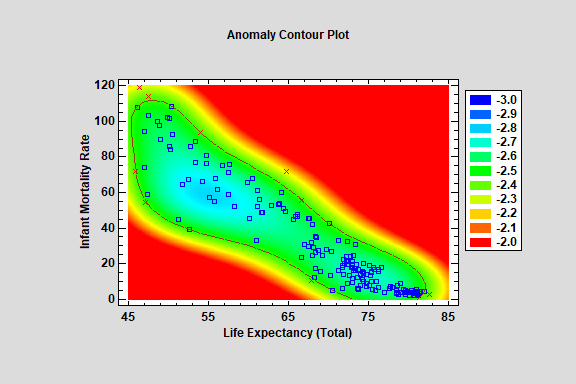
Isolation Forest
The Isolation Forest procedure implements a machine-learning process to identify potential outliers or other anomalies in a set of multivariate quantitative variables. It does so by creating a forest of decision trees and measuring how many splits are required to isolate each observation. The primary output of the procedure is an anomaly score, which is related to the average number of required splits amongst the trees. The higher the score, the more likely it is that a particular observation is an outlier.
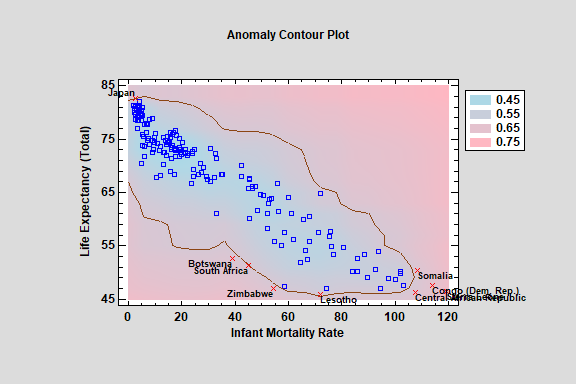
Local Outlier Factor
The Local Outlier Factor procedure implements a machine-learning process to identify potential outliers or other anomalies in a set of multivariate quantitative variables. It does so by calculating the “local reachable density” of each observation and comparing it to its nearest neighbors. Observations with substantially lower density than their neighbors are classified as outliers.
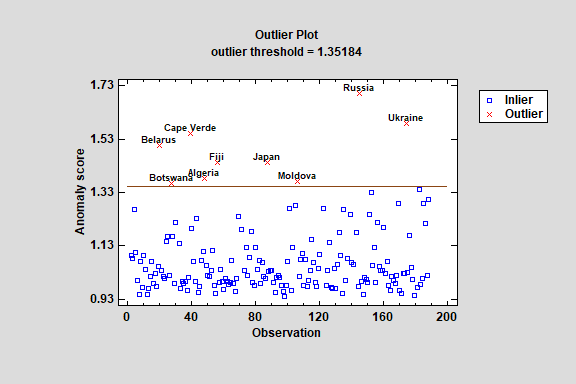
One-Class SVM
The One-Class SVM (Support Vector Machine) procedure implements a machine-learning process to identify potential outliers or other anomalies in a set of multivariate quantitative variables. It does so by transforming the data to a higher dimensional space and searching for a hypersphere or hyperplane that separates the majority of the observations from the outliers.