Machine Learning
Supervised machine learning (SML) is an important component of AI (Artificial Intelligence). It is a general term for analytic methods that construct predictions for unknown outcomes by tuning a specified model or algorithm to the known outcomes of a training data set. The outcomes may be categorical in nature (for example, whether or not a patient has a suspected disease) or quantitative (for example, the annual claims of an individual applying for insurance). SML methods rely on the speed and power of modern computers to test various parameter combinations and derive a trained algorithm that can be used to predict future outcomes.
Statgraphics Version 20 has added an interface to 10 SML methods found in the Python Scikit-Learn library. An SML Assistant has also been developed that guides users in applying multiple techniques to their data and determining which method or methods give the best predictions, as well as finding good settings for each method’s parameters.
Supervised Machine Learning Assistant
The SML Assistant guides the user through a 5-step process to develop predictions for their data.

Step 1: Selects the target variable and the features that will be considered as potential predictors.
Step 2: Divides the cases into training, test and prediction sets.
Step 3: Sets the values of any SML Assistant options.
Step 4: Applies one or more of 10 methods to construct predictive models.
Step 5: Uses the models to make predictions for cases in which the target value is unknown.
When comparing different methods, the SML Assistant provides a comparison of the methods based on how well each method performed on the training set and also during validation. Validation may be done by withholding some cases with known outcomes and putting them in a test set that is not used to train the model, or through internal cross-validation. Performance is summarized by the percentage of correct predictions for classification models and by R-squared for regression models. Final predictions may be made using either the best model or through a weighted ensemble of several of the best models.
For classification problems, a classification table is provided that shows the performance of the selected method. It included statistics such as precision, recall and F1 which are based on the number of false positives, true positives, and false negatives.

The 10 ML methods implemented are described briefly below.
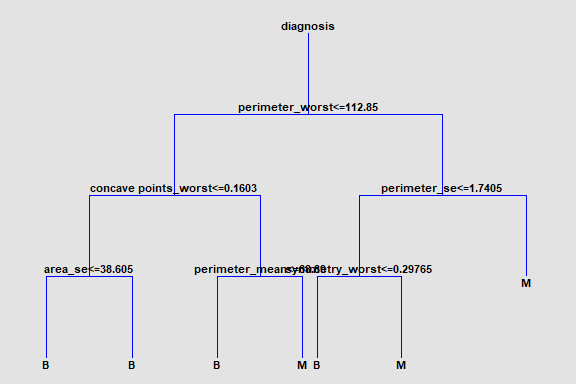
Decision Trees
These methods create a tree, each node of which corresponds to a binary decision. Given a particular observation, one travels down the branches of the tree until a terminating leaf is found. Each leaf of the tree is associated with a predicted category or value.
Decision Forests
These methods create multiple decision trees, identical to the Decision Trees. However, the final predicted value for an observation is based on combining the predictions of the ensemble of trees.
Discriminant Analysis
Discriminant analysis is a statistical procedure that creates either of 2 types of classification models that divide observations into groups based on their observed features:
Linear models that divide the observations into groups using lines or hyperplanes.
Quadratic models that formulate nonlinear functions to divide the groups.
Gaussian Processes
Gaussian processes provide a probability distribution for possible functions relating the output and the features.
Gradient Boosted Trees
This method combines multiple weak learning decision trees into an ensemble that usually outperforms a single tree. It combines multiple weak trees into a single strong model.
Linear Models
The predictions provided by this statistical procedure are based on a linear combination of the input features. Ordinary least squares is used to estimate regression models. Logistic regression is used to estimate classification models. An option is provided to automatically select a subset of the features if the training data appear to be overfitted.
Nearest Neighbors
The K Nearest Neighbors methods predict observations based on the observed output of an unknown case’s k nearest neighbors.
Naive Bayes Classifier
The Naïve Bayes method implements Bayes theorem to determine the probability that an unclassified case has a particular outcome value. It is very fast, since it assumes that all features affect the outcome independently.
Neural Networks
The neural networks implemented in this procedure represent a type of deep learning called Multilayer Perceptons (MLPs). They extend the concept of the normal linear model by adding one or more hidden layers between the input features and the target variable. Consequently, the resulting models may have many more coefficients than the number of input features.
Support Vector Machines
In the case of Support Vector Classifiers (SVC), algorithms attempt to divide observations into groups by generating gaps between the groups that are as wide as possible. In Support Vector Regression (SVR), algorithms attempt to minimize the coefficients of a model in which the distance of observations form a region around the fitted model defined by an acceptable amount of error.
For some methods, special graphs display the results.