Cluster Analysis
3 new machine learning procedures have been added to Version 20 to group multivariate data into clusters. These procedures supplement the Hierarchical Clustering and K-Means procedures found in earlier versions.
Affinity Propagation
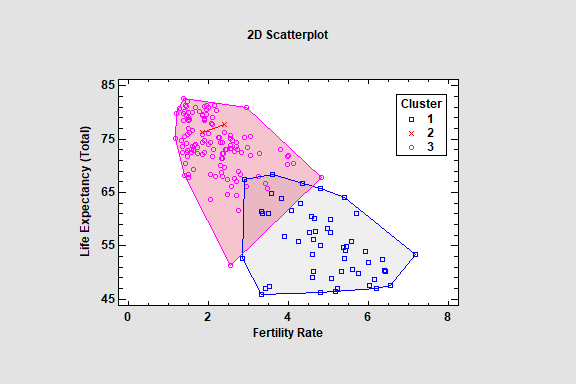
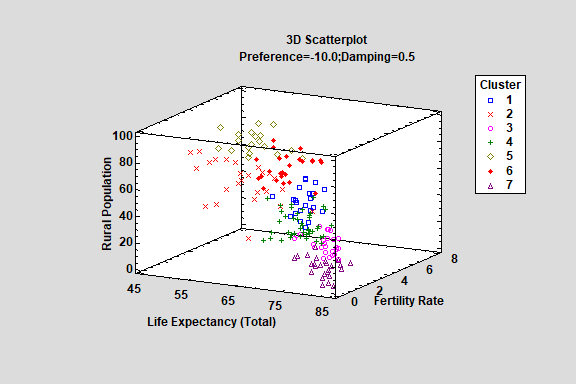
The Affinity Propagation procedure implements a machine-learning process to create groups or clusters of multivariate quantitative variables. A distinct advantage of affinity propagation is that it does not require the user to specify the number of clusters. Instead, it searches for exemplars, which are observations that best represent a set of observations that are then placed in a cluster.
DBSCAN
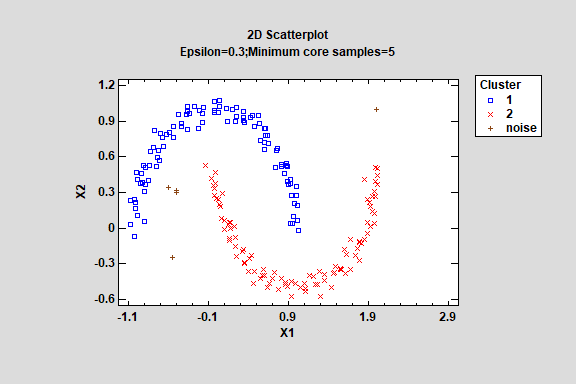
The DBSCAN procedure (Density-Based Spatial Clustering of Applications with Noise) is another machine-learning process that creates groups of multivariate quantitative variables. It is capable of identifying high-density clusters of arbitrary shapes. Two distinct advantages of DBSCAN over other clustering techniques are:
- It does not require that the user specify beforehand the number of clusters present in the data.
- Observations in low-density areas may be classified as noise and not assigned to any cluster.
Spectral Clustering
The Spectral Clustering procedure creates clusters by grouping observations which are close together in the space of the input variables. It was first introduced in Version 19.7 as an alternative to Statgraphics' K-Means Clustering procedure.

Cluster members may be plotted in either 2D or 3D.